First, we must define what is network uptime? Network uptime refers to the time it takes for a network to be up and running. With the mass exodus from private network infrastructure to cloud computing, business leaders are always focused on finding vendors that can meet their performance requirements. One important discussion point revolves around the 9s of availability and protecting against the risk of downtime. As a society, we live in a world of instant access to everything. Who wants to wait for anything? We expect to have 24/7 nonstop access to the internet. We also expect 24/7 access to our bank or credit union.
As banking adjusted to the realities of COVID-19, the industry has become hyper-focused on improving its digital offerings. Having your infrastructure always available is more critical than ever before. Your customers see all of your channels as an extension of your branch and expect whether they are on your mobile banking app or website to be able to do transactions, get support or shop for products and services. They are demanding 24/7 access to your Chatbots, live chat, contextual widgets and search tools across your different channels.
What Do “9s” Mean, Anyway?
While 100% network uptime is your goal, how close can you get without breaking your budget? Every cloud service provider and data center provide its customers with a service level agreement (SLA) that stipulates (among other things) the amount of time their systems will be up and running throughout the year. This is critically important for financial institutions that demand high levels of system availability to deliver their products and services. A good SLA should cover a variety of factors, but none are more important than network uptime reliability.
Here’s where all those 9s of availability come in. Network uptime reliability is generally expressed as a percentage that gets as close as possible to perfection. In theory, the more 9s of availability, the more time servers will be up and running throughout the year.
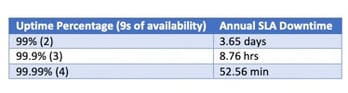
As you can see, the 9s of availability in an SLA downtime provision make a huge difference in service expectations. A data center that provides 99.99% system availability is quite a step above a facility that offers 99.9% uptime.
IT Downtime Factors
The industry average cost of IT downtime is dependent on a lot of areas. The monetary losses vary when you consider your revenue, industry, the actual duration of the outage, the number of people impacted, the time of day, etc. For example, losses are significantly higher per hour for businesses who are based on high-level data transactions, like banks and online retail sales. If you experience an unplanned outage during peak traffic time, obviously the damage will be more significant.
According to Gartner, the average cost of IT downtime is $5,600 per minute. Because there are so many differences in how businesses operate, downtime, at the low end, can be as much as $140,000 per hour, $300,000 per hour on average, and as much as $540,000 per hour at the higher end.
98% of organizations say a single hour of downtime costs over $100,000. 81% of respondents indicated that 60 minutes of downtime costs their business over $300,000. 33% of those enterprises reported that one hour of downtime costs their firms $1-5 million.
Additional Costs of IT Downtime
But there are other costs that don’t often show up in dollar form. That’s the cost of interruptions, especially when IT professionals are interrupted from what might be more productive work.
Take, for example, the interruption that occurs when someone pops into your office to tell you that your email server is down. That interruption, of course, takes the time it takes, plus the time to fix the problem. But did you know, according to a study by UC Irvine, that it often takes an average of 23 minutes to refocus and get your head back in the game after an interruption?
As once reported in the Washington Post, interruptions consume, on average, 238 minutes per day. In addition, the time to get started back up after an interruption consumes another 84 minutes a day. The time lost to stress and fatigue steals another 50 minutes a day.
All that adds up to about 6.2 hours per day, or 31 hours per week lost to interruptions! Is it any wonder we’re spending most of our time treading water?
The truth is that no business is immune to the corrosive effects of downtime when it comes to customer — as well as employee — retention, productivity, and standing in the marketplace. Downtime is extremely expensive, and in ways that can make or break the success of your organization. At the same time, it’s essentially unavoidable, because technology architectures are becoming increasingly complex and unpredictable.
Disaster Avoidance Architecture
Experts agree that one of the best ways to achieve maximum uptime is to implement a Disaster Avoidance (DA) Cloud Architecture. The concept of DA focuses on operating your infrastructure simultaneously at two geographically dispersed data centers. Your infrastructure is running in parallel thus reducing your exposer to system down time. Disaster Avoidance (DA) is a business continuity approach characterized by the agility to operate services from multiple production datacenters throughout the year. DA replicates from the live to secondary site with near real time replication and tapeless backup technology. Implementing a strategy to rotate your live and secondary sites every 6 months ensures that your site transition processes are kept up to date and working as designed. An added benefit of DA is the elimination of traditional annual DR testing. This type of redundancy removes disaster recovery from the Financial Institution’s disaster planning equation, rendering DR a moot point. This is huge in the eyes of your regulatory bodies such as the FFIEC, OCC, and FDIC.
Capitalizing on disaster avoidance vs. backup and recovery will help your institution, not only gain competitive advantage, but also drive revenue growth.



.svg)
