What We Offer
join our blog
Go to
jackhenry.com
join our blog









































































































































































































































-1.png?)


-1.png?)

























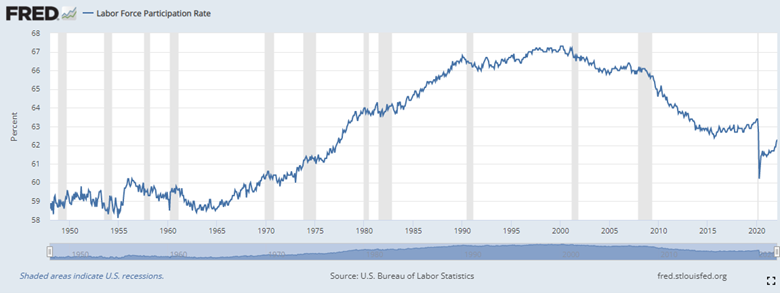























.png?)
.png?)